Semantic
TellusR’s semantic search excels at understanding user intent, making it robust against misspellings, synonyms, and general topic identification—unlike traditional keyword search, which relies strictly on exact wording.
At its core, TellusR integrates a powerful NLP module capable of handling multiple languages. By default, it includes pre-trained models optimized for common search-related use cases, eliminating the need for additional training. These models generate embeddings for both documents and queries, allowing searches to return the most relevant results based on vector similarity.
Setting Up Semantic Search
To enable semantic search, you must first create one or more semantic indexes.
During initial setup — either when installing TellusR or creating a new project — you’ll get the option to create default semantic indexes. If you select this option, the following sematic indexes will be created for your project:
- a main index for general text content, and
- a title index focused on document titles.
This combination provides a strong foundation for semantic relevance and ranking from the outset.
If you skip the initial setup or need additional indexes later, you can create and manage them at any time via the projects widget.
A semantic index is a searchable index created by converting your documents into vector representations, known as embeddings. These embeddings capture the meaning and context of the content, allowing for more intuitive and context-aware search results.
Once a semantic index is set up, any new documents sent to TellusR via the API will automatically be added—provided they contain the necessary fields for indexing.
Run a search
After importing data and creating at least one semantic index, you can test the search from:
- the dashboard (search box at the top), or
- the query-endpoints available in our API
The default behavior is that queries performed with the /tellusr/api/v1/{project}/query GET and POST operations target the keyword index and all semantic indexes, and their results are merged.
When performing a search in the dashboard, the normalized semantic scores are displayed like this in the search result list:
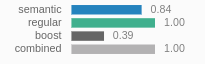
By default, semantic results are blended 50/50 with the regular search results. You can change this balance with the semantic weight control — use the “Semantic Weight”-slider to the right of the search results list, or set the semanticWeight parameter via the API (see Query Behavior below).
Best Practices
- If you upload documents using
/upload-file, the system extracts semantically meaningful chunks into thecontent_segmentfield. - Use
content_segmentas your primary semantic input field to ensure high-quality chunking. - Avoid long free-text fields or fields with low semantic value (e.g. numerical IDs, metadata).
If you have uploaded data to tellusr using the file uploading endpoints, e.g. /tellusr/api/v1/{project}/upload-file,
then the recommended setting is to make semantic indexes use content_segment (and maybe a few other metadata fields).
This field is parsed from the pdfs/word-docs in such a way to that it represents semantically relevant chunks of the document with respect to the
document structure.
Do NOT select fields, such that their field-values combined becomes much longer than a hundred words.
So avoid using fields with large field values and instead rely on smaller fields like content_segment,
which is a chunked version of uploaded file content.
Only use fields whose content as text is descriptive of the document. Avoid numeric fields and attributes that
do not carry any semantically meaningful content.
Query Behavior
Querying with semantic search:
- All semantic (and regular) indexes within a project are queried by default using
/tellusr/api/v1/{project}/query. - Results from all matching indexes are merged automatically.
- To control how results are weighted, use the
semanticWeightparameter:semanticWeight=1returns only semantic hits.semanticWeight=0returns only regular hits.- Values between
0and1(e.g.0.5) blend semantic and keyword-based results.
- When checking results in the search result list in the administration interface, normalized semantic scores are displayed for better interpretability.
Indexing
Documents uploaded via the API are indexed automatically. If needed, an option to reindex all documents from scratch are available in the the projects widget.
Next step: Enabling generative capabilities
TellusR includes several generative AI features, such as chatting with the data. A natural next step after setting up the search, is to enable this feature. You can find setup instructions for the document chat here. Once the document chat is set up, you can finetune the chat output by editing the prompts in the prompts widget.